As an early adopter who has been active on social media since 2011 (and created my first accounts around 2007), I’ve developed a long-standing love-hate relationship with social media, though the latter sentiment has increasingly grown in me in recent years. I am talking about Instagram, TikTok, Snapchat, Facebook, and more. While Twitter and LinkedIn are slightly different beasts, my concerns apply to them as well.
Let’s start with the business model of these companies, as once you understand it, the rest makes sense. It revolves around three steps: attract as many users as possible, keep them locked in at all costs, and show them as many ads as possible, which creates a vicious cycle of user entrapment.
My biggest issue with social media companies is that they intentionally create harmful products. If you find yourself stuck scrolling through social feeds for hours every day, it’s an intentional trap set by the smart people who design these sophisticated mechanics.
Take Stories, for example, a format that has been adopted by all platforms. This feature exploits people’s Fear-Of-Missing-Out (FOMO) at its worst. The same goes for the Feeds, which don’t even show updates from the people you are subscribed to, instead displaying random content meant to engage you. The fact that Instagram and others don’t have clickable links goes against the core fundamentals of the World Wide Web as a place where you can freely surf around with hyperlinks.
These platforms use manipulation techniques similar to those used in slot machines that offer intermittent rewards to keep users hooked. This unpredictability makes it difficult for users to disengage, always hoping for the next dopamine hit. Privacy exploitation is another major concern that grows larger in me. And again, it’s not a ‘bug’, but a feature of these platforms.
It’s bad, unhealthy, and I even dare to say harmful by design.
Now, you may wonder, how come I am criticising social media while posting on those very platforms?
That’s where the ‘love-hate’ part comes into play. I don’t want to demonise social media completely. Whether we like it or not, these platforms are powerful tools for spreading the word. They allow us to discover interesting content and connect with people across the globe that might not have been possible otherwise. However, it’s crucial to recognise that these benefits come despite the design of these platforms, not because of it. While they offer avenues for meaningful interaction, their primary design is focused on engagement and profit, at the expense of our well-being.
I think of social media as alcohol consumption. For those who choose to drink, it might be fun to have a pint with friends, but I think we can all agree that drinking for four, six, or even eight hours a day is considered damaging. Social media consumption should probably be treated the same way, at least for kids and adolescents until they reach the appropriate age. As a dad, I definitely don’t want my kid to be exploited by those products.
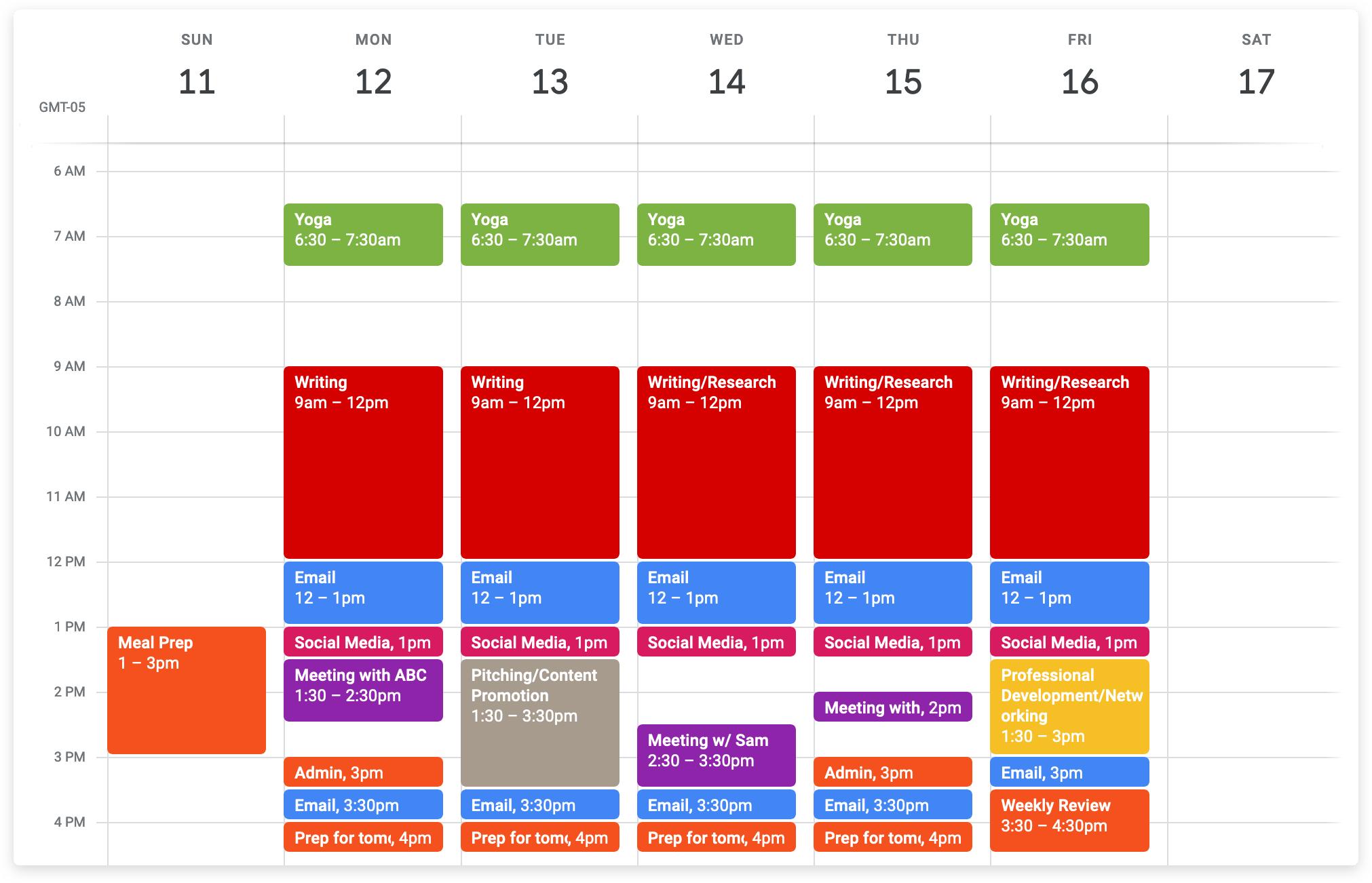
For me, I find being intentional about my social media usage is the key. I don’t have any social media apps on my phone. I use them only on the desktop, which alone I find eliminates a lot of obsessive-compulsive behaviour with checking the phone all the time. When I want to share something, I go to these platforms with that specific intention in mind. On average, my social media usage is about one hour a week, which is likely the least I can get given some of my obligations.
I must be a terrible ‘friend’ because I rarely ‘like’ or comment on other friends’ content, though I’m trying. That makes me feel disconnected at a time, and even selfish, I admit. But that’s the sacrifice I am willing to take for the sake of my mental peace.
Social media are likely here to stay, so I need to learn how to live with them.